
👑 RAG 评估--Dingo框架
时不时的就会看到有文章再说RAG已死,然后举例 Claude Code使用grep检索代码。因此在开始之前,我们先明确一下RAG的定义
RAG(Retrieval-Augmented Generation,检索增强生成)的本质是:
先检索,再生成
因此:
- 不论是否使用向量检索(Vector DB)
- 只要存在“检索 + 生成”的流程
都可以归类为 RAG 系统。
在实际工程场景中,比如要做产品问答,售后客服的时候,面对多文档 + 快速检索需求时,RAG 依然是最优解之一。
RAG评估的核心问题
一个完整的RAG 流程:
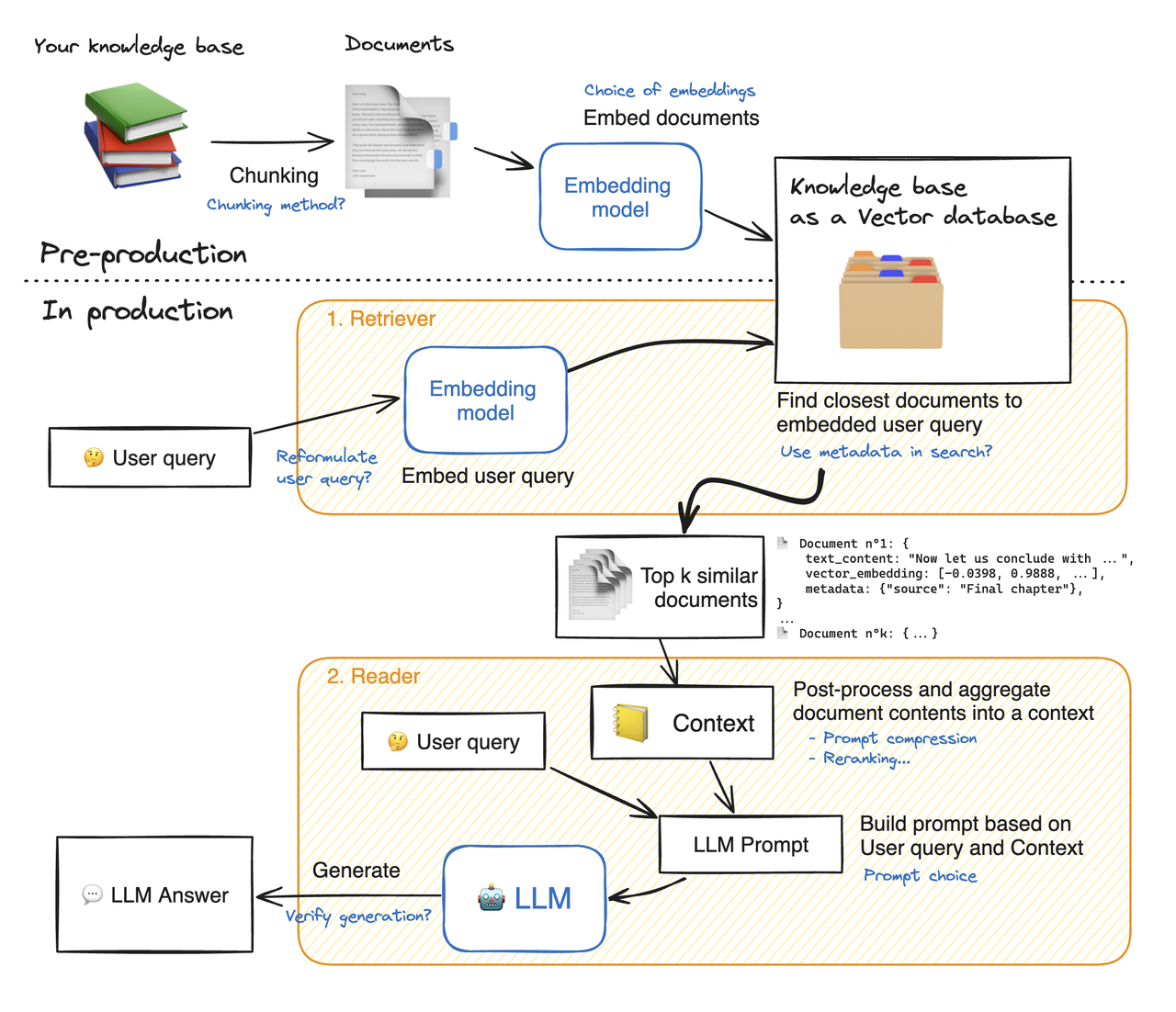
如图,RAG任何一个环节的改动都会影响性能,并且会传递,因此如果无法监控更改对系统性能的影响,那么改进就没有方向。
一个 RAG 系统的质量,本质上取决于三个问题:
- 检索是否找对(Recall / Relevancy)
- 排序是否合理(Precision)
- 生成是否可信(Faithfulness / Relevancy)
评估框架选择
Dingo简单介绍
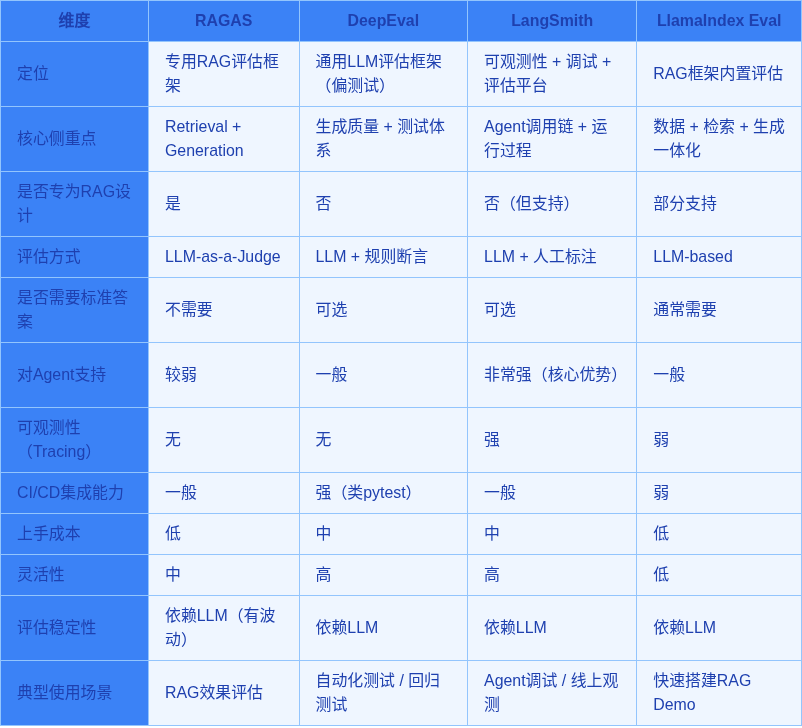
上面是常见的几个评估框架,不过我们要选择的是Dingo
它支持三类核心评估方式:
- 基于规则的确定性校验,用于快速过滤格式错误、结构异常等问题;
- 基于大模型的语义评估,用于判断回答的相关性、正确性与一致性;
- 基于本地模型的推理评估,在保障隐私与成本可控的前提下完成自动化评分。
在工程集成层面,Dingo 提供了较完善的使用方式,包括 CLI 工具与 SDK,能够方便地嵌入到现有的 AI 应用架构中。同时对于评估结果,Dingo会有一个数据图表,方便写进报告。当然更吸引我的是
“原汤化原食”:中文 RAG 系统,应优先使用中文 Prompt 进行评估
这点在实际评估中非常关键:
- 英文评估 Prompt 会引入额外语义偏差
- 中文数据 + 中文评估,结果更稳定、更可信
RAG评估的核心指标
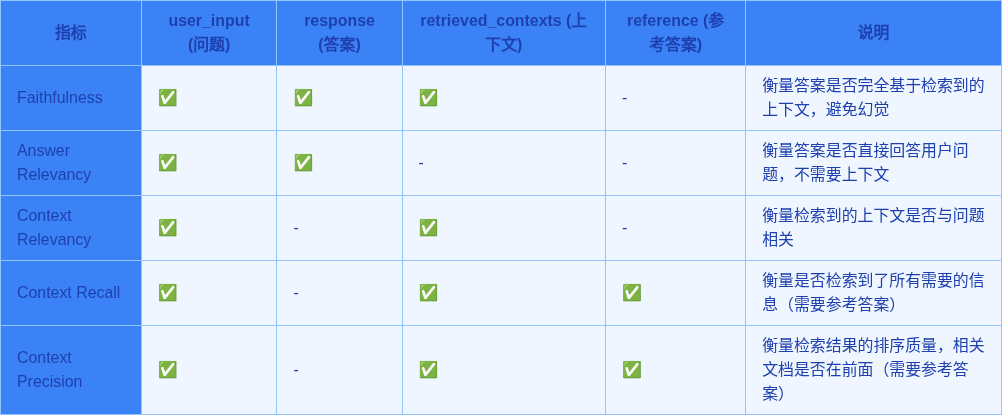
以下内容主要来源Dingo RAG 评估指标说明文档
Faithfulness(答案忠实度)
评估目标: 衡量答案是否完全基于检索上下文,避免幻觉
计算流程:
- 将答案拆解为多个陈述(claims)
- 判断每个陈述是否被上下文支持
- 计算比例
公式:
Faithfulness = (被支持的陈述数 / 总陈述数) × 10
输入:
- user_input
- response
- retrieved_contexts
推荐阈值:7 / 10
核心价值:
- 防止幻觉(最关键指标)
- 生产环境必须关注
Answer Relevancy(答案相关性)
评估目标: 衡量答案是否“真正回答了问题”
计算流程:
- 基于答案生成 N 个反问题(由 LLM 从答案推断出的问题)
- 计算生成问题的 embedding 与原始问题 embedding 的余弦相似度
- 答案相关性 = 所有相似度的平均值
公式:
Answer Relevancy = (1/N) × Σ cosine_sim(E_gi, E_o)
输入:
- user_input
- response
- embedding_config(必须)
推荐阈值:5 / 10
特点:
- 不依赖上下文
- 专注“是否跑题”
Context Relevancy(上下文相关性)
评估目标: 检索结果是否“相关”
计算流程:
评判员1 评分(Judge 1):
- 任务: 判断上下文是否包含回答问题所需的信息
- 0 = 上下文完全不相关
- 1 = 上下文部分相关
- 2 = 上下文完全相关
评判员2 评分(Judge 2):
- 使用不同的提示词表述,从另一个角度评估
- 同样使用 0-2 的评分标准
- 目的: 减少单一提示词的偏差
公式:
Context Relevancy = (相关上下文数 / 总上下文数) × 10
输入:
- user_input
- retrieved_contexts
推荐阈值:5 / 10
特点:
- 不依赖答案
- 纯检索能力评估
Context Recall(上下文召回)
评估目标: 是否“找全了信息”
计算方式:
- 从参考答案(reference)中提取独立陈述
- 对每个陈述判断是否能从检索到的上下文中归因
- 召回率 = (上下文支持的参考陈述数 / 参考中总陈述数) × 10
- 判断是否被上下文覆盖
公式:
Context Recall = (被支持的参考陈述数 / 总陈述数) × 10
输入:
- user_input
- retrieved_contexts
- reference(必须)
推荐阈值:5 / 10
核心意义:
- 防止“少说”(信息缺失)
- 与 Faithfulness 互补
Context Precision(上下文精度)
评估目标: 检索排序是否合理(Top-K 质量)
计算方式:
- 对Topk 判断该上下文是否相关(是否支持参考答案)
- 计算每个位置的精度
- 使用相关性指示器(v_k)加权求和
公式:
Context Precision = Σ(Precision@k × v_k) / 相关项总数
输入:
- user_input
- retrieved_contexts(有序)
- reference(必须)
推荐阈值:5 / 10
核心价值:
- 优化排序模型(rerank)
- 提升 Top-K 质量
评估数据集构建
方法一:LLM 自动生成
流程:
- 从知识库抽文档
- LLM 生成 Q&A
- 构建评估集
问题:
LLM 既当“出题人”,又当“判卷人”,可信度有限
方法二:真实用户数据(推荐)
我的实践方案:
- 搭建内部 ChatBot
- 员工真实提问
- 收集问答对
- 错误答案 → 人工修正
- 形成高质量参考答案
推荐使用该模块快速搭建,https://github.com/vercel/chatbot
优势:
- 更真实
- 覆盖长尾问题
- 能持续迭代
在实践该方案还有一个优点,很多企业是没有积累知识库的,前提能用于知识库构建的文件非常的少,因此有很多“员工知道,但知识库没有”的内容(暗知识),通过搭建Chatbot,这些知识就会自然暴露出来。并同时反哺知识库。
Dingo配置评估
评估
Dingo评估配置的示例代码
import asyncio import logging import os # Dingo 框架评测相关依赖 from dingo.config import InputArgs from dingo.exec import Executor from dingo.io.output.summary_model import SummaryModel from dotenv import load_dotenv load_dotenv() # 配置日志 logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s') logger = logging.getLogger(__name__) # 配置 OpenAI OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "") OPENAI_BASE_URL = os.getenv("OPENAI_BASE_URL", "") OPENAI_MODEL = os.getenv("OPENAI_MODEL", "") EMBEDDING_API_KEY = os.getenv("EMBEDDING_API_KEY", "") EMBEDDING_BASE_URL = os.getenv("EMBEDDING_BASE_URL", "") EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "") def print_metrics_summary(summary: SummaryModel): """打印指标统计摘要""" if not summary.metrics_score_stats: print("⚠️ 没有指标统计数据") return print("\n" + "=" * 80) print("📊 RAG 评估指标统计") print("=" * 80) for field_key, metrics in summary.metrics_score_stats.items(): print(f"\n📁 字段组: {field_key}") print("-" * 80) for metric_name, stats in metrics.items(): display_name = metric_name.replace("LLMRAG", "") print(f"\n {display_name}:") print(f" 平均分: {stats.get('score_average', 0):.2f}") print(f" 最小分: {stats.get('score_min', 0):.2f}") print(f" 最大分: {stats.get('score_max', 0):.2f}") print(f" 样本数: {stats.get('score_count', 0)}") if 'score_std_dev' in stats: print(f" 标准差: {stats.get('score_std_dev', 0):.2f}") overall_avg = summary.get_metrics_score_overall_average(field_key) print(f"\n 🎯 该字段组总平均分: {overall_avg:.2f}") metrics_summary = summary.get_metrics_score_summary(field_key) sorted_metrics = sorted(metrics_summary.items(), key=lambda x: x[1], reverse=True) print("\n 📈 指标排名(从高到低):") for i, (metric_name, avg_score) in enumerate(sorted_metrics, 1): display_name = metric_name.replace("LLMRAG", "") print(f" {i}. {display_name}: {avg_score:.2f}") print("\n" + "=" * 80) def run_dingo_evaluation(rag_output_path: str) -> SummaryModel: """使用 Dingo 框架评测 RAG 输出""" llm_config = { "model": OPENAI_MODEL, "key": OPENAI_API_KEY, "api_url": OPENAI_BASE_URL, # LLM 服务地址 "embedding_config": { # ⭐ 必需:Embedding 配置 "model": EMBEDDING_MODEL, "api_url": EMBEDDING_BASE_URL, # 如果同一服务提供 embedding "key": EMBEDDING_API_KEY }, "parameters": { "strictness": 3, "threshold": 5 } } input_data = { "task_name": "agent_eval_answer_relevancy", "input_path": rag_output_path, "output_path": "outputs/", "dataset": { "source": "local", "format": "jsonl", }, "executor": { "max_workers": 1, "batch_size": 1, "result_save": { "good": True, "bad": True, "all_labels": True } }, "evaluator": [ { "fields": { "prompt": "user_input", "content": "response", "reference": "reference", "context": "retrieved_contexts" }, "evals": [ { "name": "LLMRAGFaithfulness", # 忠实度 "config": llm_config }, { "name": "LLMRAGContextPrecision", # 检索精度 "config": llm_config }, { "name": "LLMRAGContextRecall", # 检索 召回率 需要 参考答案 "config": llm_config }, { "name": "LLMRAGContextRelevancy", # 检索上下文相关性 "config": llm_config }, { "name": "LLMRAGAnswerRelevancy", # 问答相关性 "config": llm_config } ] } ] } logger.info("开始使用 Dingo 评测...") input_args = InputArgs(**input_data) executor = Executor.exec_map["local"](input_args) summary = executor.execute() return summary async def main(): print("=" * 80) print("RAG 【问答相关性能】系统评测 by Dingo") print("=" * 80) summary = run_dingo_evaluation("conversations.jsonl") print("\n" + "=" * 80) print("✅ 评测完成!") print("=" * 80) print(f"总数据量: {summary.total}") print(f"通过: {summary.num_good}") print(f"未通过: {summary.num_bad}") print(f"通过率: {summary.score}%") print_metrics_summary(summary) print(f"\n💾 详细结果已保存到: {summary.output_path}") if __name__ == "__main__": asyncio.run(main())
评估数据集conversations.jsonl示例
{"user_input": "", "response": "", "reference": "", "retrieved_contexts": ""}
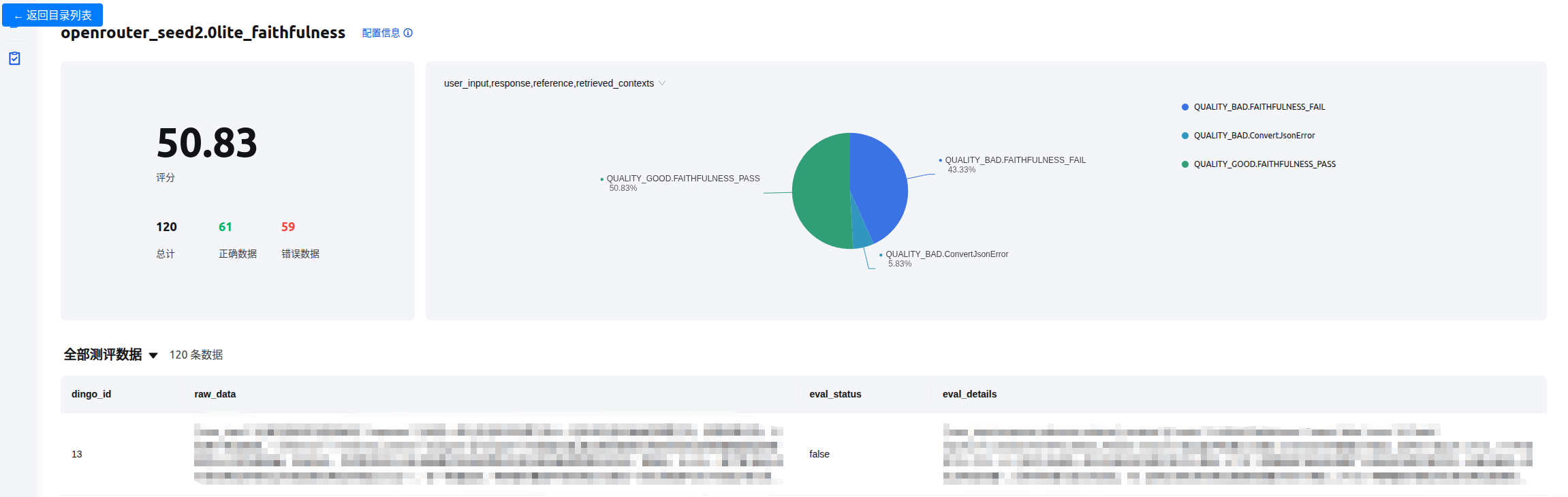
查看结果
Dingo自带结果可视化页面
python -m dingo.run.vsl --port 8999 --input outputs
最后
RAG 系统(知识库):是一个持续迭代的工程,没有什么完美的解决方案
只有:
持续评估 → 持续优化 → 持续迭代